Since deploying my latest web application, a Los Angeles Neighborhood Ranker, I've wanted to explain the process of gathering the data. The first step was to decide which neighborhoods to use, what they're called, and how they're defined, geographically. The first stop I made is the LA Times Mapping LA project. It has a mapping feature… Continue reading Collecting Neighborhood Data
Month: October 2016
Ranking Neighborhoods in Los Angeles
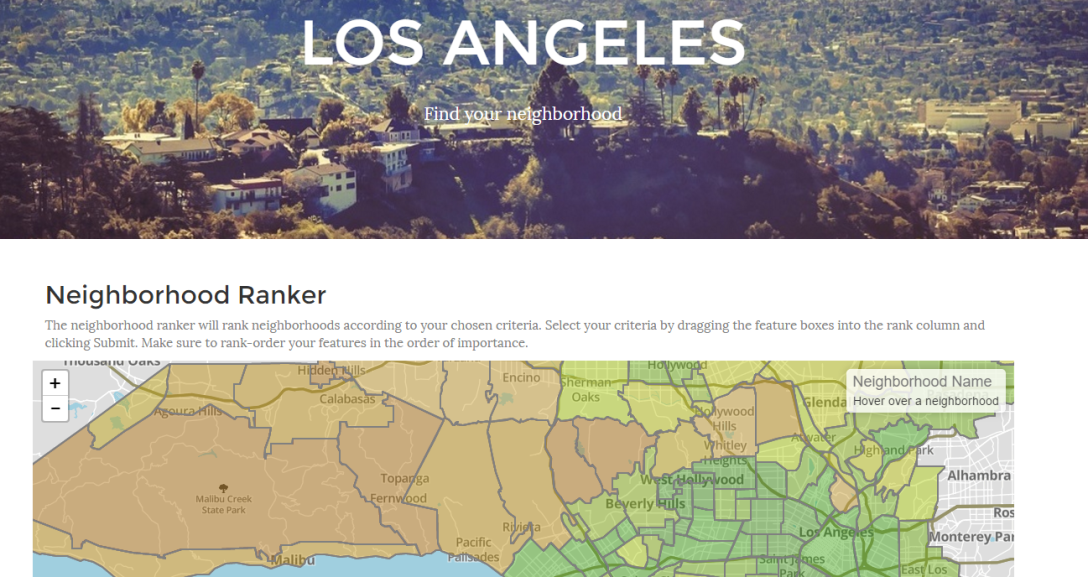
My latest web application is an interactive, personalized map-based ranking of neighborhoods in Los Angeles. I've spent the last few weeks gathering data points for each of 155 neighborhoods in the Los Angeles area. That on its own could (and will soon) be the topic of its own post. For now, I wanted to explain the ranking… Continue reading Ranking Neighborhoods in Los Angeles
